本文分享一些中文內碼的心得:
中文編碼五花八門,以前有IBM主機編碼、倚天編碼、資策會 Big5、CNS中文標準交換碼、萬國碼(UTF)...等,另外,還有一些擴編的變形,現在主流的編碼是UTF-8,它涵蓋全世界大部分的語文,因此,作業系統編碼大部分是以UTF-8為預設值,以Windows作業系統為例,可使用 MS Word 查到UTF-8內碼,選擇『插入』>『符號』>『其他符號』,點選任何一個字,例如下圖,『一』的內碼是0x4e00,0x代表16進位,4e00是16進位的內碼值。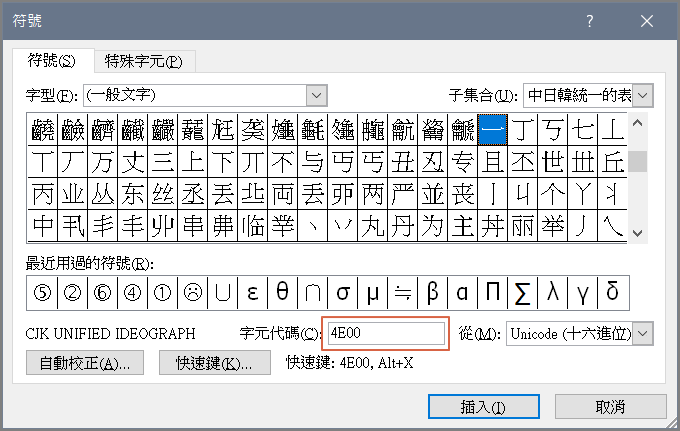
圖一. Windows 內碼查詢
Python同時支援Big5、UTF-8編碼,也支援大陸的GBK編碼,我們來小玩一下:
ord('一') # output:19968
hex(ord('一')) # output:0x4e00
果然是0x4e00,與圖一相符。可以驗算一下。
# 驗算 0x4e00 = ?
4*16**3+14*16**2 # output:19968
f"{ord('一'):x}" # output:4e00
讀者可以試試其他的字,例如日文ぁ,內碼為0x3041。
chr(19968) # output:'一'
或是
chr(0x4e00) # output:'一'
for i in range(10):
print(chr(ord('一')+i), end='')
# 一丁丂七丄丅丆万丈三
for i in range(83):
print(chr(ord('ぁ')+i), end='')
# ぁあぃいぅうぇえぉおかがきぎくぐけげこごさざしじすずせぜそぞただちぢっつづてでとどなにぬねのはばぱひびぴふぶぷへべぺほぼぽまみむめもゃやゅゆょよらりるれろゎわゐゑをん
除了ord、chr函數外,encoding/decoding更可以支援各種各種編碼的轉換,但他們有點複雜,以UTF-8為例,每個字的內碼長度是不固定的,可以是1~4 bytes,ASCII code前128個字符是1個byte,而漢字大部分是3個byte,如下圖,每個byte前面都有固定的bit,以識別編碼。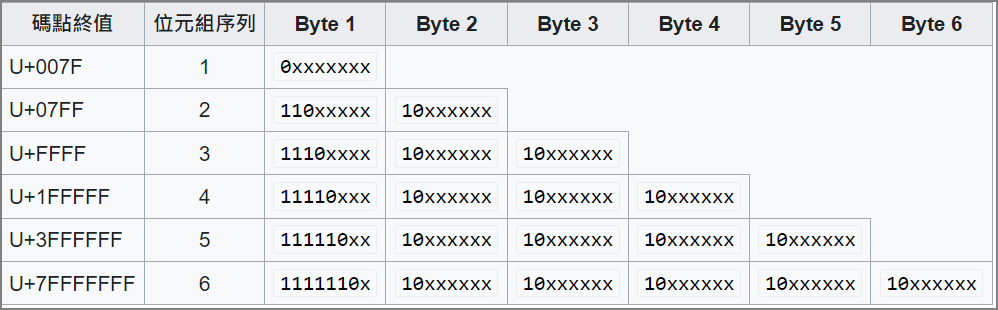
圖二. UTF-8 碼位,圖片來源:維基百科 UTF-8
以下就來實驗encode/decode用法。
'一'.encode('utf8') # output:b'\xe4\xb8\x80'
'一'的內碼果然是3個byte。
f'{0xe4b880:b}' # output:'111001001011100010000000'
仔細比對一下,固定的bit如下圖的框,與圖二相符。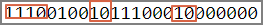
圖三. 固定的bits
x = b'111001001011100010000000'
int(x[4:8] + x[10:16] + x[-6:], 2) # output:19968
與ord('一')結果相同,真的成功看懂UTF-8文件了。瞭解這個,我們要進行文件轉碼,就沒有問題了。
x = f"{int.from_bytes('一'.encode('utf8'), 'big'):b}"
int(x[4:8] + x[10:16] + x[-6:], 2) # output:19968
'一二三四'.encode('utf8') # output:b'\xe4\xb8\x80\xe4\xba\x8c\xe4\xb8\x89\xe5\x9b\x9b'
'一二三四'.encode('utf8').decode('utf8') # output:'一二三四'
使用爬蟲,有時候抓回來的網頁出現亂碼,通常是因為該網頁為Big5編碼,可以使用下列指令轉為字串。
b'\xa4@\xa4G\xa4T\xa5|'.decode('big5') # output:'一二三四'
Big5的中文內碼一律採用2 bytes,範圍在0xa440~0xf9d5之間,而且中間有空隙。
# 讀取 CNS2BIG5.txt
import pandas as pd
df = pd.read_csv('./CNS2BIG5.txt', sep='\t', header=None, names=['cns', 'big5'])
df.head()
顯示100個中文字:
for no, i in enumerate(df['big5'].values):
if no > 100: break # 顯示100個中文字
print(int(i, 16).to_bytes(2, 'big').decode('big5'), end='')
輸出結果:
一乙丁七乃九了二人儿入八几刀刁力匕十卜又三下丈上丫丸凡久么也乞于亡兀刃勺千叉口土士夕大女子孑孓寸小尢尸山川工己已巳巾干廾弋弓才丑丐不中丰丹之尹予云井互五亢仁什仃仆仇仍今介仄元允內六兮公冗凶分切刈勻勾勿化
如要顯示所有中文字,可將第2行刪除。
# 合併CNS_phonetic.txt、CNS2BIG5.txt,找到中文內碼與注音對照表
df_all = df.merge(df2, on='cns')
df_all.head()
查詢『埠』:
x = f"{int.from_bytes('埠'.encode('big5'), 'big'):x}".upper()
df_all.query('big5 == @x')
執行結果: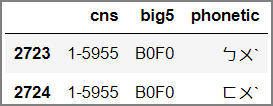
查詢『熵』:
x = f"{int.from_bytes('熵'.encode('big5'), 'big'):x}".upper()
df_all.query('big5 == @x')
執行結果: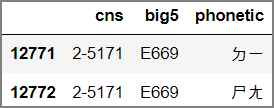
事實上,『熵』應念為第2個,音同『商』。
還可以作更多的延伸,例如:
 I code so I am
I code so I am
